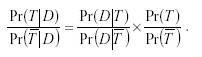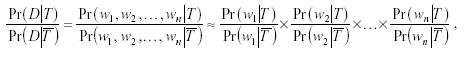![]()
![]()
|
|
INTRODUCTION:
A central problem in information retrieval is the automated classification of text documents. Given a set of documents, and a set of topics, what is sought is an algorithm that can determine whether or not each document is about each topic. The
Document Classifier / Text Classifier that I’ve built works on 2 algorithms
namely: Naïve
Bayes Space Vector Bayesian
Classification: A
first psychological insight into the text classification problem involves the
relationship between the decisions “this document is about this topic” and
“this document is not this topic”. When people are asked to make this
decision, they actively seek information that would help them make either
choice. They do not look only for confirming information in the hope of
establishing that the document is about the topic, and conclude otherwise if
they fail to find enough information. For
example, if people are asked whether a newspaper article is about the US
Presidential Elections, and they are only shown the word “The”, most would
not be able to make any decision with any degree of confidence. If, however,
they were shown the word “Cricket”, most people would confidently respond
‘No’. The fact that people are able to decide to answer ‘No’ in the
second case suggests that they are actively evaluating the word as evidence in
favour of the document not being about the topic. Neither the word ‘The’ nor
‘Cricket’ provide any significant evidence in favour of the document being
about the topic (as, for example, the word “Gore” would), yet a decision can
be made on the basis of the word ‘Cricket’. Formal
Specification Under
a Bayesian analysis (see, for example, Kass and Raftery, 1995), it is possible
to generate the posterior odds that a particular text document is about a
particular topic. This is achieved by combining two measurable probabilities:
the prior odds, and the evidence. The prior odds relate to the
probability that the document is about the topic, before any of the content of
the document has been considered. These odds may be estimated from the base-rate
with which documents about that topic have been observed to occur in the current
information environment. The evidence relates to the probability that a
particular document would have been generated, under the assumption that it is
(or is not) about a particular topic. These probabilities must be estimated from
a consideration of the content of the current text document, and transform the
prior odds into posterior odds. In this sense, the content of the document
provides evidence for or against the document belonging to the topic. The
relationship Posterior Odds = Evidence x Prior Odds may be
formalized as follows:
Where
D is a document, T is “about a topic” and T is “not about a
topic”. The challenge in the Bayesian analysis is to quantify the probability
that a particular document would be observed, given the presence or absence of a
particular topic. It seems natural (although there are other possibilities) to
represent a document in terms of the sequence of words it contains. Given this
assumption, the problem is to quantify the probability that the sequence of
words arises given the presence or absence of a topic. The word-based
probability estimation can then be made tractable by assuming that the evidence
provided by each word applies independently. This is almost certainly not true,
but does seem likely to provide a reasonable approximation in many cases. In
particular, the independence assumption has some justification when dealing with
text documents that are intended to convey information using simple and direct
prose. Formally,
this may be written:
Where
k
w is the k-th word out of a total of n words in
the document D. One
way to estimate these probabilities is by measuring word frequencies across a
set of ‘training’ documents. For those documents in the training set that
are about a particular topic, the number of times that word occurs, as a
proportion of the total number of words in those documents, gives an estimate of
the probability with which that word occurs in documents about the topic. An
analogous frequency can be calculated across the documents in the training that
are not about the topic, and used to estimate the probability with which the
word occurs in documents that are not about the topic. Zero empirical
frequencies may be replaced by a small probability value. Vector
Space Model:
|